Reactive Programming, a powerful paradigm in modern software development, revolutionizes the way we handle data and events. By embracing reactive principles, developers can build highly responsive and scalable applications. In this tutorial, we will explore the fundamentals of Reactive Programming, its benefits, common use cases, and delve into real-world examples to demonstrate its practical applications.
What is Reactive Programming?
Reactive programming is a programming paradigm that focuses on building applications that are responsive, resilient, and scalable. At its core, reactive programming is centered around the concept of reacting to changes and events in a system. It allows developers to design applications that can handle and process streams of data in an efficient and non-blocking manner.
In reactive programming, the emphasis is placed on asynchronous and event-driven programming models. This means that instead of following a traditional sequential approach, where tasks are executed one after another, reactive programs respond to events and data changes as they occur. By leveraging this approach, developers can build applications that are more flexible and can handle large amounts of data and concurrent requests effectively.
For instance, in imperative programming, the statement a := b + c assigns the value of b + c to a at the moment of evaluation. Subsequently modifying the values of b or c does not affect the value of a. However, in reactive programming, the value of a is automatically updated whenever b or c changes, eliminating the need to re-execute the a := b + c statement to determine the current value of a.
Benefits of Reactive Programming
Reactive programming offers several benefits that make it a compelling choice for modern application development:
- Responsiveness: Reactive applications are designed to be highly responsive and provide a better user experience. By handling events and data changes in an asynchronous and non-blocking manner, reactive programs can swiftly react to user interactions and deliver real-time updates.
- Scalability: Reactive programming enables the development of highly scalable applications. It allows for efficient handling of concurrent operations and can easily adapt to varying workloads, ensuring that the system remains responsive even under heavy loads.
- Resilience: Reactive programs are built to be resilient and handle failures gracefully. With built-in error handling and recovery mechanisms, reactive applications can recover from failures and maintain system integrity without compromising overall performance.
- Composition and Reusability: Reactive programming promotes a functional programming style, where data transformations and operations are expressed using composable functions. This allows for better code reuse, maintainability, and modularity.
Common Use Cases for Reactive Programming
Reactive programming finds utility in a wide range of use cases, including:
- User Interfaces: Reactive programming can enhance user interface development by enabling real-time updates and interactive user experiences. It is particularly useful for building dynamic web applications, responsive mobile applications, and interactive dashboards.
- Event Processing: Reactive programming is well-suited for event-driven systems. It can handle event streams efficiently, making it suitable for applications such as real-time analytics, IoT data processing, and financial systems that require continuous data processing.
- Streaming and Batch Processing: Reactive programming is effective in handling streaming data and batch processing tasks. It can process large volumes of data in a reactive and efficient manner, making it suitable for applications such as log analysis, data pipelines, and data-intensive systems.
- Distributed Systems: Reactive programming is beneficial in the development of distributed systems, where components need to communicate and react to events across a network. It can help in building scalable microservices architectures, distributed messaging systems, and collaborative applications.
By harnessing the power of reactive programming, developers can create applications that are more responsive, scalable, and resilient, catering to the demands of modern software development.
Understanding Reactive Streams
Reactive Streams is a specification that provides a standard way to deal with asynchronous, non-blocking streams of data. It offers a set of interfaces, rules, and guidelines that enable efficient and consistent handling of data streams in reactive programming.
In simple terms, reactive streams allow us to process data as it becomes available, rather than waiting for the entire data set to be ready. This approach enables us to build responsive and scalable applications that can handle large volumes of data efficiently.
Key Components of Reactive Streams
To understand reactive streams, it’s essential to grasp the three key components involved: Publisher, Subscriber, and Subscription.
- Publisher: The Publisher represents the source of data in a reactive stream. It produces and emits data items asynchronously. Think of it as a provider or producer of data. It can emit any number of items to its Subscribers.
- Subscriber: The Subscriber consumes the data emitted by the Publisher. It defines the operations to be performed on the data and how to handle it. It receives the emitted items one by one and processes them asynchronously. A Subscriber can subscribe to multiple Publishers.
- Subscription: The Subscription acts as a contract between the Publisher and Subscriber. It allows the Subscriber to request and control the flow of data. Through the Subscription, the Subscriber can request a specific number of items it wants to receive from the Publisher. It also provides methods to cancel the subscription when the Subscriber no longer needs the data.
To delve deeper into these components, I highly suggest exploring the tutorial titled Reactive Programming: Creating Publishers and Subscribers in Java. It offers valuable insights and in-depth knowledge on the topic.
Flow Control Mechanisms (Backpressure)
One of the essential aspects of reactive streams is flow control, which ensures that the data processing doesn’t overwhelm the downstream components, especially when there’s a significant difference in processing speeds between the Publisher and Subscriber.
Flow control is achieved through a mechanism called backpressure. Backpressure allows the Subscriber to signal to the Publisher how much data it can handle at a given time. It helps prevent data overflow and provides a way to control the rate at which data is emitted.
In the context of a reactive application, let’s understand backpressure with an illustrative example:
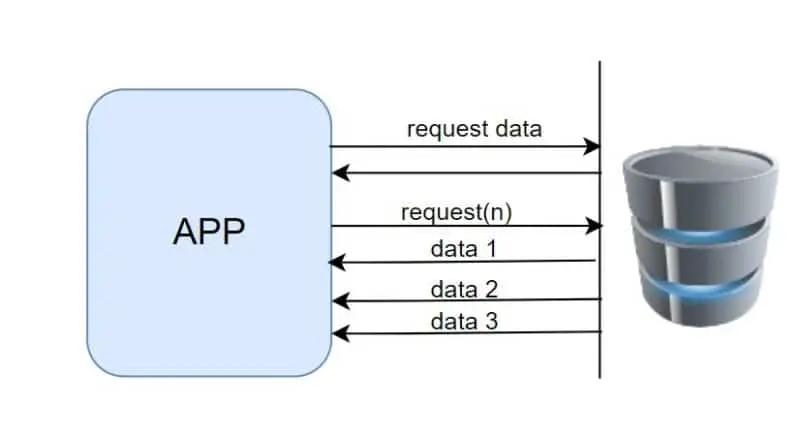
Consider the scenario depicted in the provided image
- The application requests data from the database.
- As soon as the database receives the call, the code returns immediately, releasing the calling thread to perform other tasks.
- Behind the scenes, another call is sent to the database to request data.
- The application, through this process, indicates to the database that it is ready to consume the data.
- The database responds by sending the data back to the application concurrently, as soon as it becomes available, in the form of a stream of events (data1, data2, data3, and so on).
However, it is possible for the emitters of data to overwhelm the consumers. To avoid this problem, the consumer should communicate to the producer the desired amount of data to be sent. This communication is what we call backpressure.
In the provided image, the second call to the DB illustrates this concept by specifying how much data we want using the “request(n)” method. Here, “n” can be replaced with any number. If we set it to 2, for example, we will receive a stream of two events.
In simple terms, backpressure allows the Subscriber to regulate the flow of data by requesting a specific number of items at a time. If the Subscriber gets overwhelmed or needs to catch up, it can reduce the number of requested items or even pause the data flow temporarily.
By using backpressure, reactive streams ensure that the data processing remains efficient and balanced, preventing resource exhaustion and maintaining stability in the system.
Reactive Programming Paradigms
In reactive programming, one of the key paradigms is asynchronous and event-driven programming. Traditional programming models often follow a sequential execution flow, where one task is completed before moving on to the next. However, in reactive programming, the focus is on handling events and asynchronous operations efficiently.
In this paradigm, events or asynchronous operations can occur independently of the main program flow. These events can be user interactions, network requests, sensor inputs, or any other kind of asynchronous task. Reactive programming allows developers to handle these events and operations in a non-blocking manner, ensuring that the program remains responsive and efficient.
The key idea is to react to events as they happen, rather than waiting for each operation to complete before moving on. Reactive programming enables you to define how your program should respond to specific events or changes in state, allowing for greater flexibility and responsiveness.
Functional Programming Principles
Another important paradigm in reactive programming is functional programming. Functional programming emphasizes the use of pure functions, which are functions that always produce the same output for a given input and have no side effects. This means that pure functions do not modify any external state or variables and only rely on their input parameters.
Functional programming in reactive programming helps to simplify the logic and make it easier to reason about the program’s behavior. It promotes immutability, where data is treated as immutable and not modified directly. Instead, new instances or transformed versions of data are created.
By leveraging functional programming principles, reactive programming enables developers to write concise, modular, and reusable code. It encourages a more declarative and expressive style, where you focus on describing what you want to achieve rather than how to achieve it.
Declarative Programming Style
Reactive programming also embraces a declarative programming style. In contrast to imperative programming, where you specify detailed step-by-step instructions, declarative programming focuses on describing the desired outcome or result.
With declarative programming, you define the behavior of your program by declaring the relationships and dependencies between different components or data streams. You express what should happen, and the underlying reactive framework takes care of orchestrating the execution and managing the flow of data.
By adopting a declarative style, reactive programming allows you to express complex interactions and transformations concisely. It abstracts away the low-level details of managing concurrency and event handling, enabling you to focus more on the overall design and logic of your application.
In summary, reactive programming encompasses asynchronous and event-driven programming, functional programming principles, and a declarative programming style. These paradigms work together to enable efficient handling of events and asynchronous operations, promote modularity and reusability through functional principles, and provide a more concise and expressive way of specifying the desired behavior through a declarative programming style.
Below are two comprehensive tutorials that delve into the distinctions between declarative programming and imperative programming:
Reactive Libraries and Frameworks
Reactive programming is supported by various libraries that provide the necessary tools and abstractions to implement reactive applications. Two popular reactive libraries are RxJava and Reactor.
- RxJava: RxJava is a library for reactive programming in Java that implements the Reactive Extensions (Rx) pattern. It provides a rich set of operators to work with reactive streams and enables developers to compose asynchronous and event-based programs.Key features of RxJava include:
- Observable: Represents a stream of data or events that can be observed.
- Operators: Allows transformation, filtering, combining, and error handling on observables.
- Schedulers: Facilitates control over concurrency and thread management.
RxJava has gained popularity due to its comprehensive API, extensive operator support, and large community.
- Reactor: Reactor is a reactive programming library for building non-blocking applications on the Java Virtual Machine (JVM). It is developed by the Spring team and provides a simple yet powerful programming model for reactive applications.Key features of Reactor include:
- Flux and Mono: Represent reactive streams, with Flux supporting multiple values and Mono representing zero or one value.
- Operators: Offers a wide range of operators for transforming, filtering, and combining streams.
- Scheduler support: Allows controlling concurrency and thread usage.
Reactor is widely used in the Spring ecosystem, making it a popular choice for building reactive applications in the Java community.Flux and Mono
Introduction to Reactive Frameworks
Reactive frameworks are higher-level abstractions built on top of reactive libraries, providing additional features and integration capabilities. Two notable reactive frameworks are Spring WebFlux and Akka.
- Spring WebFlux: Spring WebFlux is a part of the Spring Framework and provides reactive programming support for building web applications. It is built on top of Reactor and offers an alternative to the traditional Spring MVC framework.Key features of Spring WebFlux include:
- Non-blocking I/O: Enables handling a large number of concurrent requests with fewer threads.
- Annotation-driven programming model: Allows writing reactive web controllers using familiar Spring annotations.
- Integration with other Spring components: Seamlessly integrates with other Spring projects like Spring Data and Spring Security.
Spring WebFlux is a popular choice for building reactive web applications within the Spring ecosystem.
- Akka: Akka is a toolkit and runtime for building highly concurrent and distributed applications. It provides a reactive programming model based on the Actor Model, which allows developers to build scalable and fault-tolerant systems.Key features of Akka include:
- Actor-based concurrency: Enables writing concurrent and distributed systems using lightweight actors.
- Fault tolerance: Provides mechanisms for handling failures and managing system resilience.
- Cluster support: Allows building distributed systems with automatic load balancing and replication.
Akka is widely used in scenarios that require high scalability and fault tolerance, such as real-time systems and distributed computing.
Comparisons and Considerations
When choosing a reactive library or framework, several factors should be considered. Here are some key points to compare and evaluate:
- Community support: Look for active communities, forums, and resources available for the library or framework. A vibrant community ensures better support and learning opportunities.
- Learning curve: Consider the complexity and ease of understanding the library or framework. Some may have steeper learning curves than others, especially for novice developers.
- Integration capabilities: Evaluate how well the library or framework integrates with other components and frameworks you plan to use in your application. Seamless integration can significantly simplify development.
- Performance considerations: Assess the performance characteristics of the library or framework, such as throughput, latency, and memory usage. Performance requirements may vary depending on your specific use case.
Key Concepts in Reactive Programming
Reactive programming introduces a set of key concepts that are fundamental to understanding and harnessing its power. In this section, we will explore these concepts, namely streams and observables, transformation operators, combining operators, and error handling strategies.
Streams and Observables
In reactive programming, streams and observables form the foundation of data flow. Think of a stream as a sequence of events or values that can be emitted over time. Streams can emit various events, including:
- Values (Results): A stream can emit values or results, which represent the data being processed. These values could be any information such as numbers, strings, objects, or even more complex data structures.
- Completed Signal: A stream can emit a “completed” signal, indicating that the stream has finished emitting all the necessary values or events. This signal is useful for notifying the subscribers that the stream has reached its end.
- Error Signal: Additionally, a stream can emit an “error” signal when an error or exceptional condition occurs during the data processing. This signal allows subscribers to handle and respond to errors appropriately.
When writing code in a reactive way, it is common to define functions that will capture the results, the completed signal, and the error signal of a stream. These functions are designed to handle these events asynchronously, ensuring that the appropriate actions are taken based on the type of event emitted.
To provide further clarity, here is an image illustrating the events emitted by streams:
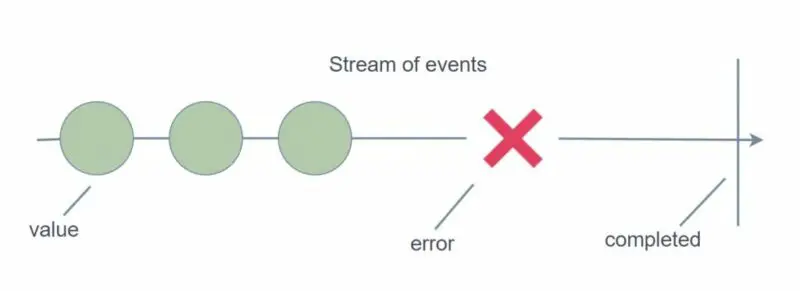
By utilizing streams and observables, developers can effectively handle asynchronous data processing while accommodating values, completion signals, and error signals in a structured manner.
Transformation operators
Transformation operators are an essential part of reactive programming, as they allow you to manipulate the emitted values within streams and observables. These operators provide a way to transform or modify the data flowing through the pipeline.
The ‘map’ operator, for example, lets you apply a function to each emitted value and return a new value based on that transformation. It allows you to convert the data from one format to another or perform calculations on it. Similarly, the ‘filter’ operator allows you to selectively filter out values based on a specified condition.
Other common transformation operators include ‘reduce,’ which aggregates values into a single result, and ‘flatMap,’ which transforms each emitted value into a new observable. These operators provide powerful capabilities for manipulating and processing data within reactive programming.
Combining operators
Combining operators are used to merge or combine multiple streams or observables into a single stream. They allow you to coordinate and synchronize the emitted values from different sources.
The ‘merge’ operator, for instance, combines multiple streams into a single stream, emitting values from all sources as they arrive. This can be useful when you need to merge data from multiple asynchronous processes or event sources into a unified stream.
The ‘zip’ operator combines values emitted by multiple streams pairwise. It waits for all the streams to emit a value and then combines them into a single value or object. This allows you to correlate related data from different sources.
Another useful operator is ‘combineLatest,’ which combines the latest values emitted by multiple streams into a single value. This is particularly helpful when you need to react to the most recent data from different sources simultaneously.
For those seeking further knowledge, the following tutorial Combine Flux and Mono Publishers presents an excellent starting point to delve deeper into the subject.
Error handling and recovery strategies
Error handling is a critical aspect of reactive programming, as it allows you to handle exceptions and errors that may occur during data processing. Reactive programming provides mechanisms to handle errors in a streamlined and efficient way.
One common strategy for error handling is using the ‘onError’ notification, which allows you to define how to handle errors within a stream. This notification ensures that if an error occurs, it is propagated downstream, providing an opportunity to handle it appropriately.
Additionally, you can use operators like ‘retry’ and ‘retryWhen’ to define recovery strategies. These operators enable you to automatically retry an operation a certain number of times or apply custom logic for determining when and how to retry.
If you are utilizing Project Reactor, this comprehensive tutorial provides in-depth guidance on effectively managing exceptions Handling Exceptions in Project Reactor.
Real-World Examples and Case Studies
Reactive programming finds its practical applications in various domains, enabling developers to tackle complex scenarios efficiently. Let’s explore some practical examples of how reactive programming can be applied:
- Real-time Data Streaming: Imagine a financial trading system that needs to process a continuous stream of market data updates and make split-second decisions. Reactive programming enables developers to handle this real-time data stream effectively by providing tools and techniques to react to incoming data events as they occur. This ensures that the system can process and respond to market changes promptly.
- User Interfaces with Real-Time Updates: Reactive programming can greatly enhance user interfaces that require real-time updates, such as social media platforms or chat applications. By leveraging reactive principles, developers can build interfaces that seamlessly react to user interactions, updates from other users, and dynamic content changes without blocking or freezing the UI. This results in a smooth and responsive user experience.
- IoT and Sensor Data Processing: The Internet of Things (IoT) involves connecting various devices and sensors to collect and process data. Reactive programming allows developers to handle the constant flow of data from these devices and react to events in real-time. For example, in a smart home system, reactive programming can be used to respond to sensor data changes and trigger appropriate actions like adjusting room temperature or turning on lights.
Success stories and notable use cases
Reactive programming has been widely adopted in various industries, leading to successful implementations and noteworthy use cases. Let’s take a look at a couple of examples:
- Netflix: One of the prominent adopters of reactive programming is Netflix, the popular streaming platform. They employ reactive programming principles to handle massive amounts of streaming data and provide a smooth, uninterrupted experience to millions of users. Reactive programming allows them to handle dynamic user demands, scale their systems efficiently, and optimize resource utilization.
- Uber: Uber, the renowned ride-sharing service, relies on reactive programming to manage their real-time tracking and dispatch system. Reactive principles help them process incoming location updates from drivers and dynamically adjust routes in response to changing traffic conditions. This allows Uber to provide accurate ETAs (Estimated Time of Arrival) and optimize their transportation network efficiently.
Conclusion
Reactive Programming has gained significant traction across industries, empowering developers to create efficient and resilient applications. By leveraging reactive libraries and frameworks, embracing functional programming principles, and employing declarative programming styles, developers can handle data streams, manage backpressure, and build systems that react in real-time.
By mastering the key concepts and techniques, you are well-equipped to unlock the benefits of Reactive Programming and take your applications to the next level of responsiveness and scalability. I encourage you to visit the Java Reactive page for additional tutorials related to this topic. Don’t miss out on exploring more valuable resources available there!